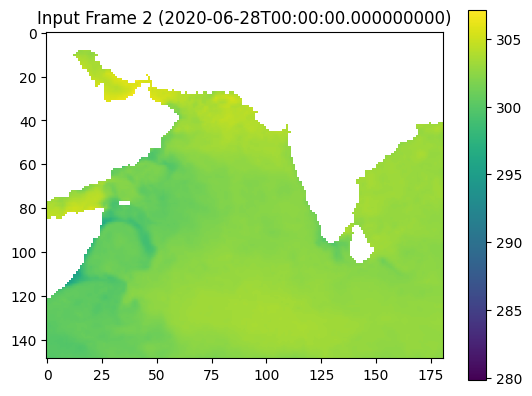
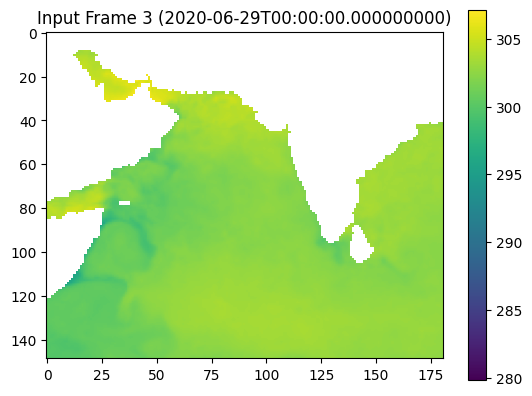
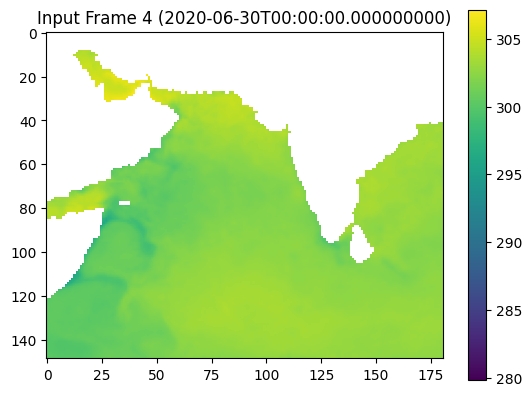
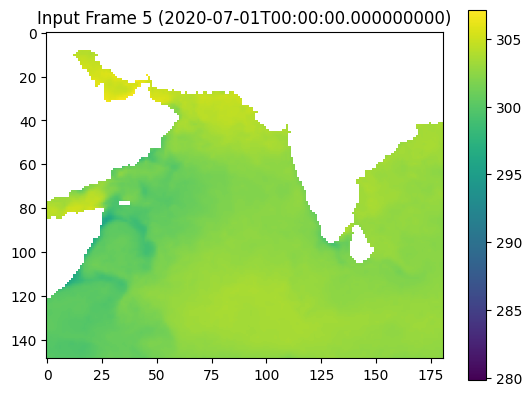
pip install xarray numpy dask matplotlibRequirement already satisfied: xarray in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (2024.5.0)
Requirement already satisfied: numpy in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (1.26.4)
Requirement already satisfied: dask in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (2024.5.1)
Requirement already satisfied: matplotlib in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (3.9.0)
Requirement already satisfied: packaging>=23.1 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from xarray) (23.2)
Requirement already satisfied: pandas>=2.0 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from xarray) (2.2.2)
Requirement already satisfied: click>=8.1 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from dask) (8.1.7)
Requirement already satisfied: cloudpickle>=1.5.0 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from dask) (3.0.0)
Requirement already satisfied: fsspec>=2021.09.0 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from dask) (2024.5.0)
Requirement already satisfied: partd>=1.2.0 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from dask) (1.4.2)
Requirement already satisfied: pyyaml>=5.3.1 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from dask) (6.0.1)
Requirement already satisfied: toolz>=0.10.0 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from dask) (0.12.1)
Requirement already satisfied: importlib-metadata>=4.13.0 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from dask) (7.1.0)
Requirement already satisfied: contourpy>=1.0.1 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from matplotlib) (1.2.1)
Requirement already satisfied: cycler>=0.10 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from matplotlib) (0.12.1)
Requirement already satisfied: fonttools>=4.22.0 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from matplotlib) (4.52.1)
Requirement already satisfied: kiwisolver>=1.3.1 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from matplotlib) (1.4.5)
Requirement already satisfied: pillow>=8 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from matplotlib) (10.3.0)
Requirement already satisfied: pyparsing>=2.3.1 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from matplotlib) (3.1.2)
Requirement already satisfied: python-dateutil>=2.7 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from matplotlib) (2.8.2)
Requirement already satisfied: colorama in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from click>=8.1->dask) (0.4.6)
Requirement already satisfied: zipp>=0.5 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from importlib-metadata>=4.13.0->dask) (3.17.0)
Requirement already satisfied: pytz>=2020.1 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from pandas>=2.0->xarray) (2024.1)
Requirement already satisfied: tzdata>=2022.7 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from pandas>=2.0->xarray) (2024.1)
Requirement already satisfied: locket in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from partd>=1.2.0->dask) (1.0.0)
Requirement already satisfied: six>=1.5 in c:\users\yuj81\anaconda3\envs\py310\lib\site-packages (from python-dateutil>=2.7->matplotlib) (1.16.0)
Note: you may need to restart the kernel to use updated packages.